Side Project · AI Product Builder 作品展示
WiPPY
用自然語言規劃活動訊息,AI 幫你寫好、排好、推出去。
AI 驅動的活動管理與訊息推播平台。透過 7 階段 Harness Pipeline, 讓每一次 LLM 呼叫都可觀測、可恢復,並透過 LINE Bot 自動推播給對的群組。
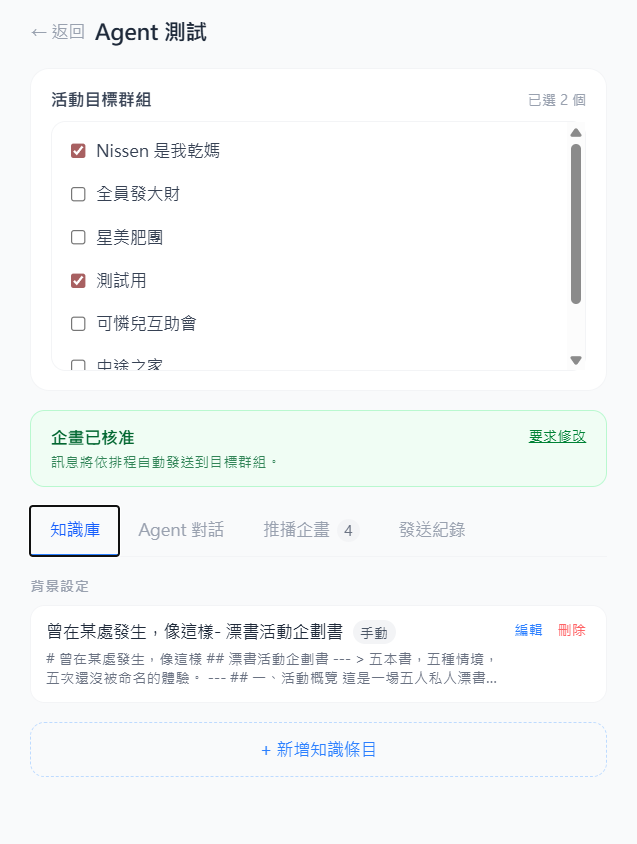
知識庫 · load_context
活動知識庫管理
儲存活動背景資料、選書哲學、氛圍調性。每次對話都會自動載入作為 LLM 的 system prompt context。
- 手動或 AI 萃取新增知識條目
- 知識內容注入 Stage 1 load_context
- 目標群組同頁管理,已選 2 個